Memorisation in generative fashions and EU copyright regulation: an interdisciplinary view – Cyber Tech
Giant language fashions’ (LLMs) best power can also be their best weak spot: their studying is so superior that typically, similar to people, they memorise. This isn’t stunning, after all, as a result of computer systems are actually good at primarily two issues: storing and analysing knowledge. There may be now empirical proof that deep studying fashions are vulnerable to memorising (i.e., storing) fragments of their coaching knowledge. Similar to the human mind must memorise fragments of data to study, so do LLMs. And once they reproduce verbatim these fragments, this can be a floor for copyright infringement.
Enter the Transformer
The transformer structure (as in Generative Pre-trained Transformer, GPT) enabled many new functions however, arguably, probably the most spectacular one stays artificial content material era, reminiscent of textual content, photos and video. The important thing to the success of transformer expertise is the flexibility to generalise, that’s, to function accurately on new and unseen knowledge. Historically, the flexibility to generalise is at odds with memorization. Memorization is very similar to in people: for those who memorize the solutions to an examination, you’ll most likely carry out properly if the examination’s questions are an identical to these you practised. However the extra you’re requested to use that information to a brand new situation the extra your efficiency drastically diminishes. You might have did not perceive what you realized; you solely memorized it. Transformers, from this perspective, work not too in another way: they intention at understanding (generalising), however they might memorise in sure conditions.
It Is essential to make clear that, from a technical perspective, transformer-based fashions encode phrases as teams of characters (i.e., tokens) numerically represented as vectors (i.e., embeddings). The fashions use neural networks to maximise the likelihood of each potential subsequent token in a sequence, leading to a distribution over a vocabulary which consists of all phrases. Every enter token is mapped to a likelihood distribution over the output tokens, that’s, the next characters. That is how transformers “perceive” (or generalise, or summary from) their coaching knowledge. The fashions, nonetheless, don’t memorise the syntax, semantics, or pragmatics of the coaching knowledge (e.g., a ebook, poem, or software program code). They as an alternative study patterns and derive guidelines to generate syntactically, semantically, and pragmatically coherent textual content. Even when the ‘supply code’ of a big language mannequin could possibly be made out there, it could be nearly unattainable to revert again to the coaching knowledge. The ebook just isn’t current within the skilled mannequin. Nonetheless, the mannequin couldn’t have been developed with out the ebook.
The various faces of memorisation
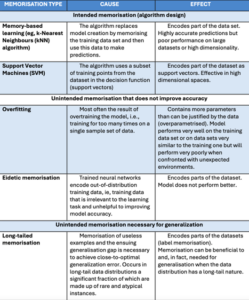
One frequent fault in non-technical literature is the frequent perception that each one machine studying algorithms behave in the identical means. There are algorithms that create fashions which explicitly encode their coaching knowledge, i.e., memorisation is an meant function of the algorithm. These are, as an illustration, the 𝑘-nearest neighbour classification algorithm (KNN), which is principally an outline of the dataset, or the assist vector machines (SVM), which embody factors from the dataset as ‘assist vectors’.
Equally, non-technical literature hardly ever distinguishes between overfitting (an excessive amount of coaching on the identical dataset which results in poor generalisation and enhanced memorisation) and types of unintended memorisation which as an alternative could also be important for the accuracy of the mannequin.
As a matter of truth, current analysis exhibits that memorisation in transformer expertise just isn’t all the time the results of a fault within the coaching course of. Take the case of the memorisation of uncommon particulars in regards to the coaching knowledge, as argued by Feldman. His speculation attracts on the long-tailed nature of knowledge distributions and purports that memorisation of ineffective examples and the following generalisation hole is critical to realize close-to-optimal generalisation error. This occurs when the coaching knowledge distribution is long-tailed, that’s, when uncommon and non-typical situations make up a big portion of the coaching dataset. In long-tailed knowledge distributions, helpful examples, which enhance the generalisation error, may be statistically indistinguishable from ineffective examples, which may be outliers or mislabelled examples. Let’s illustrate this with the instance of birds in a group of photos. There could also be hundreds of various varieties or species of birds, and a few subgroups might look very totally different due to totally different ranges of magnification, or totally different physique components, or backgrounds which can be highlighted within the picture. If the photographs are categorised merely as ‘birds’ with out distinguishing between particular subgroups, and if the educational algorithm hasn’t encountered sure representatives of a subgroup throughout the dataset, it would battle to make correct predictions for that subgroup on account of their variations. Since there are lots of totally different subpopulations, a few of them might have a low frequency within the knowledge distribution (e.g., 1 in ). For a subgroup of birds, it could be that we’d solely observe one instance in the whole coaching knowledge set. Nonetheless, one can also be the variety of outliers our algorithm would observe. The algorithm wouldn’t be capable of distinguish between one thing genuinely uncommon and an outlier that doesn’t signify nearly all of the information. Equally, in areas the place there’s a low confidence, the algorithm wouldn’t be capable of inform a “noisy” instance from a accurately labelled one. If a lot of the knowledge follows a sample the place some sorts of birds are very uncommon and others are extra frequent, these uncommon occurrences can really make up a good portion of the whole dataset. This imbalance within the knowledge could make it difficult for the algorithm to study successfully from it.
Lengthy-tailed knowledge distributions are typical in lots of crucial machine studying functions from face recognition, to age classification and medical imaging duties.
Desk 1 Completely different types of memorisation
The Textual content and Information Mining (TDM) exceptions and the era of artificial content material
The provisional compromise textual content of the AI Act proposal appears to make clear past any doubt (if there was any) that CDSMD’s TDM exceptions apply to the event and coaching of generative fashions. Subsequently, all copies made within the course of of making LLMs are excused throughout the limits of Artwork. 3 and 4 CDSMD. Within the CDSMD there appears to be a type of implicit assumption that these copies will occur within the preparation section and never be current within the mannequin (e.g. Rec. 8-9). In different phrases, the problem of memorization was circuitously addressed within the CDSMD. Nonetheless, the beneficiant construction of Arts. 2 – 4 CDSMD is arguably sufficiently broad to additionally cowl everlasting copies finally current within the mannequin, an interpretation that might excuse all types of memorization. It needs to be famous, after all, {that a} mannequin containing copyright related copies of the coaching dataset can’t be distributed or communicated to the general public, since Artwork. 3 and 4 solely excuse reproductions (and within the case of Artwork. 4 some variations).
Relating to the output of the generative AI software and whether or not copyright-relevant copies finally current there are additionally lined by Artwork. 3 and 4 the scenario is much less clear. Nonetheless, even when these copies could possibly be seen as separate and unbiased from the following acts of communication to the general public, this answer can be fairly ephemeral on the sensible stage. In actual fact, these copies couldn’t be additional communicated to the general public as a result of exact same causes identified above (Arts. 3 and 4 solely excuse reproductions, not communications to the general public). The required conclusion is that if the mannequin generates outputs (e.g., a solution) which will qualify as a replica in a part of the coaching materials, these outputs can’t be communicated to the general public with out infringing on copyright.
A scenario the place the generative AI software doesn’t talk its mannequin however solely the generated outputs (e.g., solutions) is completely believable, and in reality makes up a lot of the present industrial AI choices. Nonetheless, an AI software that doesn’t talk its outputs to the general public is just onerous to picture: it could be like having your AI app and never be capable of use it. After all, it’s potential to have the outputs of the mannequin circuitously communicated to the general public however used as an middleman enter for different technical processes. Present developments appear to be within the course of making use of downstream filters that take away from the AI outputs the parts that might signify a replica (partially) of protected coaching materials. This filtering might naturally be accomplished horizontally, or solely in these jurisdictions the place the act could possibly be thought of as infringing. On this sense, the deployment of generative AI options would possible embody components of copyright content material moderation.
Ought to all types of memorisation be handled the identical?
From an EU copyright perspective, memorisation is just a copy of (a part of) a piece. When this copy triggers Artwork. 2 InfoSoc Directive it requires an authorisation, both voluntary or statutory. Nonetheless, if we settle for that there’s certainly a symbiotic relationship between some types of memorisation and generalisation (or much less technically, studying), then we might argue that this second sort of memorisation is critical for improved (machine) studying. In distinction, overfitting and eidetic memorisation aren’t solely not crucial for the aim of abstraction in transformer expertise however they’ve a unfavorable influence on the mannequin’s efficiency.
Whereas we confirmed that EU copyright regulation treats all these types of memorization on the identical stage, there could also be normative area to argue that they deserve a distinct therapy, significantly in a authorized surroundings that regulates TDM and Generative AI on the identical stage. As an illustration, a lot of the litigation that’s rising on this space is based on an alleged diploma of similarity between the generative AI output and the enter works used as coaching materials. When the similarity is enough to set off a prima facie copyright declare it could possibly be argued that the presence or absence of memorization could also be a decisive think about a discovering of infringement.
If no memorization has taken place, the straightforward “studying” accomplished by a machine shouldn’t be handled in another way from the straightforward studying accomplished by a human. Then again, if memorization was current “unintentionally” the dearth of intention might warrant some mitigating consequence to a discovering of infringement, illustratively, by the use of decreasing and even excluding financial damages in favour of injunctive reduction (maybe mixed with an obligation to fix the infringing scenario as soon as notified, equally to Artwork. 14 e-Commerce Directive, now Article 6 of the Digital Companies Act.). Lastly, conditions the place memorisation was meant or negligently allowed could possibly be handled as regular conditions of copyright infringement.
Naturally, the one approach to show memorisation can be to have entry to the mannequin, its supply code, its parameters, and coaching knowledge. This might grow to be an space the place conventional copyright guidelines (e.g., infringement proceedings) utilized to AI programs obtain the accent perform of favouring extra transparency in a area generally criticised for its opacity or “black field” construction. Copyright 1, AI 0!
If you wish to dig deeper into this dialogue, please take a look at the preprint of our paper which gives an intensive dialogue of memorisation by way of the lens of generative fashions for code. This analysis is funded by the European Union’s Horizon Europe analysis and innovation programme beneath the 3Os and IP consciousness elevating for collaborative ecosystems (ZOOOM) venture, grant settlement No 101070077.

Victor Blanco Receives 2024 Don Sweat Award for Exemplary Marine Extension Work in Taylor County – Cyber Tech

secondary use of well being information within the EHDS framework – European Legislation Weblog – Cyber Tech

Missverständnisse zur Mietpreisbremse – Cyber Tech
About The Author
admin
Azeem Rajpoot, the author behind This Blog, is a passionate tech enthusiast with a keen interest in exploring and sharing insights about the rapidly evolving world of technology. With a background in Blogging, Azeem Rajpoot brings a unique perspective to the blog, offering in-depth analyses, reviews, and thought-provoking articles. Committed to making technology accessible to all, Azeem strives to deliver content that not only keeps readers informed about the latest trends but also sparks curiosity and discussions. Follow Azeem on this exciting tech journey to stay updated and inspired.
